

Während die Generative Künstliche Intelligenz (GKI) immer beliebter wird, bleibt die Tendenz der Technologie, Antworten zu fingieren, ein großes Manko. Wir glauben, dass spezialisierte Modelle entwickelt werden können, um Halluzinationen zu reduzieren und die Genauigkeit und Effizienz der Künstlichen Intelligenz für den Einsatz in Anlageanwendungen zu verbessern.
Wenn Sie im letzten Jahr mit ChatGPT oder GKI-gesteuerten Anwendungen experimentiert haben, waren Sie wahrscheinlich erstaunt und auch skeptisch. Die Technologie hat uns mit ihrer Fähigkeit verblüfft, intelligente Zusammenfassungen zu schreiben, Gedichte zu verfassen, Witze zu erzählen und Fragen zu einer Reihe von Themen in bemerkenswert gut geschriebener Prosa zu beantworten. Allerdings neigt sie auch dazu, Informationen zu fälschen – je nach Modell in 3% bis 27% der Fälle, wie eine Studie des KI-Start-ups Vectara ergab. Während diese Fehlerquote bei Unterhaltungsanwendungen tolerierbar sein mag, müssen die Halluzinationen von Generativer Künstlicher Intelligenz eingedämmt werden, damit Anleger ein hohes Maß an Vertrauen in den Output von Generativer Künstlicher Intelligenz für Portfolios gewinnen können.
Warum halluziniert die Generative Künstliche Intelligenz?
Die Magie der Generativen Künstlichen Intelligenz steckt in großen Sprachmodellen (Large Language Models, LLMs). „Large Language Models“ sind Algorithmen, die auf Deep-Learning-Technologie basieren und Texte und andere Formen von Inhalten erkennen, zusammenfassen, übersetzen, vorhersagen und generieren können. Das Wissen, das diese Modelle antreibt, basiert auf riesigen Datensätzen und den statistischen Wahrscheinlichkeiten des Auftretens von Wörtern und Wortfolgen in einem bestimmten Kontext.
Der Aufbau umfangreicher Modelle ist jedoch mit Kosten verbunden. „Large Language Models“ sind Generalisten, sie werden also auf allgemeinen Daten trainiert, die im Internet zu finden sind, ohne dass die Quelle einer Faktenprüfung unterzogen wird. Diese Modelle können auch versagen, wenn sie mit unbekannten Daten konfrontiert werden, die beim Training nicht berücksichtigt wurden. Und je nachdem, wie der Benutzer das Modell auffordert, kann es Antworten geben, die einfach nicht wahr sind.
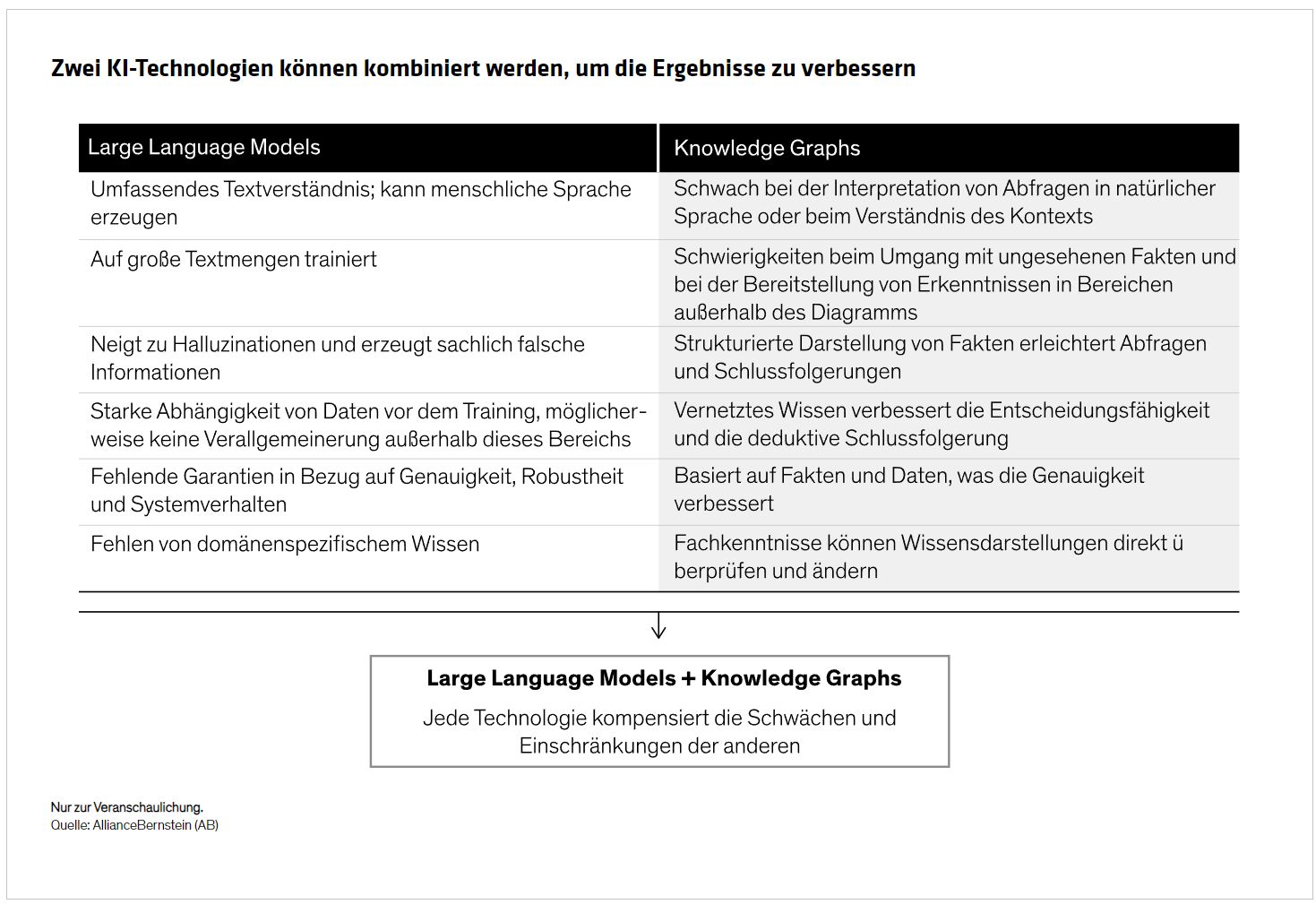
Die Beseitigung von Halluzinationen ist ein Hauptanliegen von GKI-Anbietern, die das Vertrauen in die Technologie und deren Kommerzialisierung stärken wollen. Wir glauben, dass der Schlüssel zur Lösung des Problems bei Investmentanwendungen in der Erstellung spezieller Modelle liegt, die das Ergebnis verbessern können. Diese kleineren Modelle sind als Wissensdiagramme (Knowledge Graphs, KGs) bekannt, die auf engeren, definierten Datensätzen aufgebaut sind. „Knowledge Graphs“ verwenden graphenbasierte Technologie – eine Art des maschinellen Lernens, die die Fähigkeit eines Modells verbessert, zuverlässige Beziehungen und Muster zu erfassen.
Spezialisierte Anwendungen sind beständiger
Die Verwendung einer graphenbasierten Modellstruktur und das Training eines KI-Gehirns auf einem kleineren, aber gezielteren Datensatz hilft, die Grenzen der Antworten einzugrenzen. Bei einer Investmentanwendung können „Knowledge Graphs“ ein Modell durch das umfangreiche Wissen des Open-Source-LLM leiten, indem sie beispielsweise die Relevanz verschiedener Begriffe bestimmen, die mit Technologie und Innovation zu tun haben können oder auch nicht (Abbildung). Während sich ein „Large Language Model“ auf die statistische Wahrscheinlichkeit des Auftretens eines Wortes in der Nähe eines anderen Wortes konzentriert, kann ein graphenbasiertes Modell zu einem zunehmend intelligenten Fachexperten werden. Es kann so konzipiert werden, dass es kausale Beziehungen zwischen Konzepten, Wörtern und Sätzen in Bereichen wie Makroökonomie, Technologie, Finanzen und Geopolitik versteht, die sich mit größerer Wahrscheinlichkeit auf die Finanzmärkte und Wertpapiere auswirken.
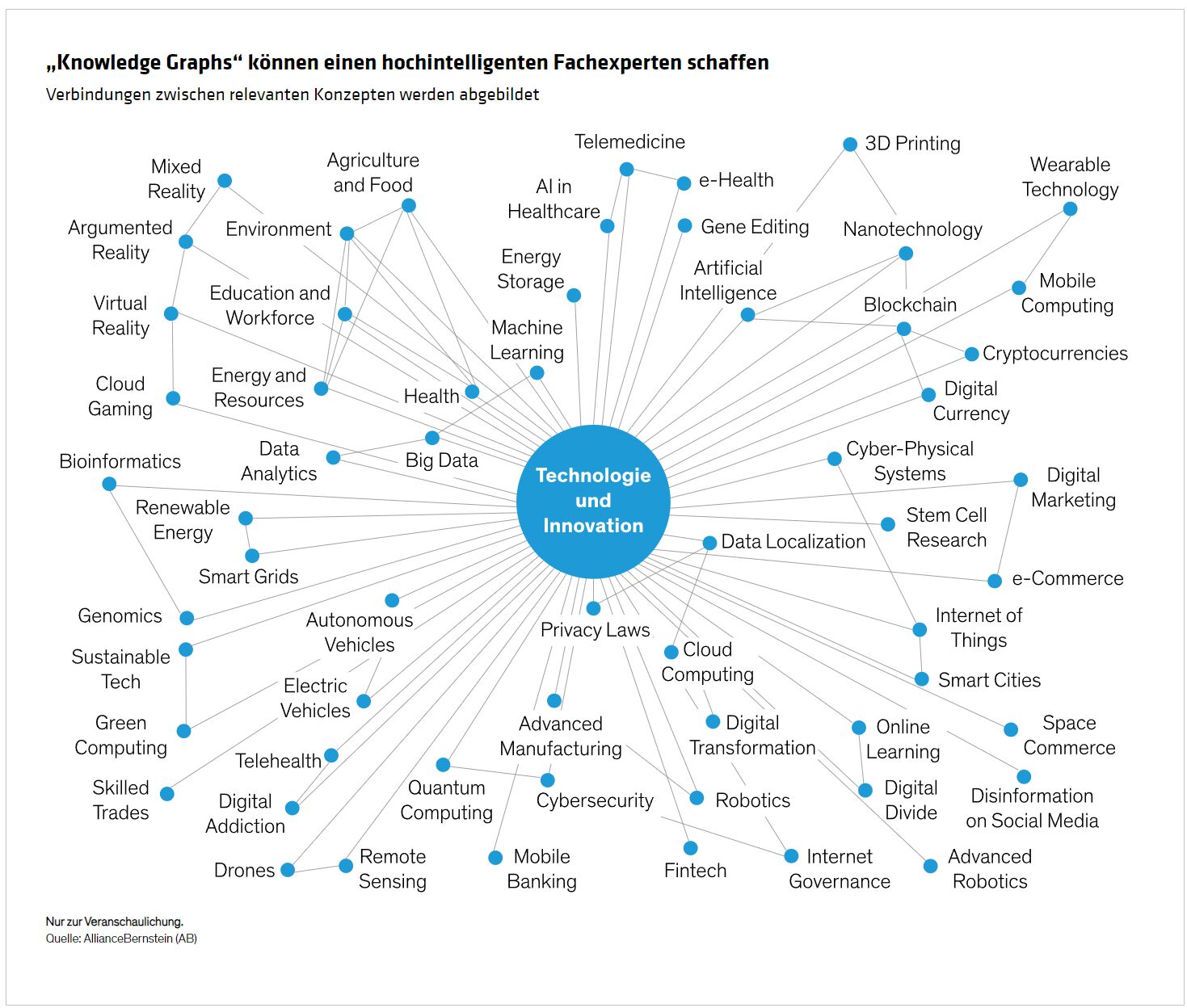
„Knowledge Graphs“ können die Genauigkeit verbessern, weil die Beziehungen zwischen den besprochenen Wörtern und Themen genauer definiert sind. Der Aufbau eines KI-Modells, das die Spezifität eines „Knowledge Graphs“ mit der Breite eines „Large Language Models“ kombiniert, kann unserer Ansicht nach für Anleger die optimale Kombination beider Welten bieten (Abbildung).
Die Zuverlässigkeit eines KG-basierten KI-Modells lässt sich auch durch die sorgfältige Auswahl von Trainingsdaten aus verifizierten Quellen mit unvoreingenommenem Wissen in einer Reihe von Bereichen verbessern. Zu den Quellen kann Material des Internationalen Währungsfonds, der Welthandelsorganisation und der globalen Zentralbanken gehören. „Knowledge Graphs“ müssen sich ständig weiterentwickeln, indem es neue Informationen aus den ausgewählten zuverlässigen Quellen aufnimmt und verarbeitet.
Qualitätskontrolle und Faktenüberprüfung
Auch die sorgfältige Zusammenstellung von KG-Schulungsmaterialien kann Halluzinationen nicht ausschließen. KI-Fachleute können bei der Erstellung eines Modells auch andere Werkzeuge einsetzen, die unserer Meinung nach zu viel vertrauenswürdigeren Ergebnissen führen können.
Zum Beispiel kann wissensbasierte Argumentation eine intelligentere Eingabeaufforderung fördern. Dazu gehört die Verwendung von „Knowledge Graphs“, um Prompts zu generieren, die auf sachlichen Informationen und geprüften Quellen beruhen. Dadurch erhalten die „Large Language Models“ einen genaueren und relevanteren Ausgangspunkt für die Erstellung seiner Ergebnisse.
Auch die Struktur von Diagrammen kann die Ergebnisse einer Faktenprüfung unterziehen. In der Tat kann eine gut konzipierte Diagrammstruktur die Zuverlässigkeit der Ergebnisse eines LLM-Modells quantifizieren und Systeme und/oder menschliche Administratoren vor möglichen Halluzinationen warnen.
Warum ist das für Anleger wichtig?
Bei Investmentmodellen muss ein KI-gesteuertes System für klar definierte Ziele ausgelegt sein. Das erfordert die Kombination verschiedener Modelle und Technologien für das angestrebte Ergebnis, zum Beispiel die Identifizierung von Wertpapieren, die aufgrund eines Ereignisses, das eine Branche betrifft, eine positive oder negative Wertentwicklung aufweisen können. Auch wenn technikfremde Anleger die Funktionsweise der Modelle möglicherweise nicht vollständig verstehen, ist es wichtig, einen Portfoliomanager, der Künstliche Intelligenz einsetzt, zu bitten, in einfacher Sprache zu erklären, wie die Modelle eine kohärente Architektur bilden, die die Anlagestrategie unterstützt.
Wir glauben, dass sich mit der richtigen Kombination von Techniken Halluzinationen in einem KI-Modell drastisch eindämmen lassen. Größere Genauigkeit ist der Eckpfeiler eines KI-Anlagegehirns, das so konzipiert werden kann, dass es jenseits traditioneller Datenquellen und quantitativer Strategien nach attraktiven Anlagen über alle Anlageklassen hinweg sucht, ungehindert von menschlichen Verhaltensvoreingenommenheiten.
In einer Welt zunehmender Unsicherheit und schnellen Wandels müssen Anleger, die aus der KI-Revolution Kapital schlagen wollen, davon überzeugt sein, dass die Technologie keine Illusion ist. Durch die Kombination von „Large Language Models“ mit fokussierten „Knowledge Graphs“ und die Einbeziehung gründlicher Risikokontrollmechanismen können systematische Plausibilitätskontrollen durchgeführt werden, um sicherzustellen, dass ein KI-gesteuertes Anlagemodell fest in einer Welt der realen Chancen verwurzelt ist.
Weitere beliebte Meldungen:



