

Daten fördern die Entscheidungsfindung
Als Leiter der Abteilung für Geschäfts- und Technologielösungen bei William Blair Investment Management ist es meine Aufgabe, Technologien in unsere Geschäftsabläufe zu integrieren - natürlich einschließlich der Anlageprozesse, aber auch in Marketing und Vertrieb.
Während sich mein Team auf technologische Lösungen konzentriert, die Data Engineering, Data Governance, Technologieentwicklung, Datenvisualisierung und Analytik umfassen, wäre Technologie ohne Daten sinnlos. Jede Entscheidung, die wir treffen, wird von Daten gestützt.
Da wir Aktien- und Anleiheportfolios verwalten, sind viele dieser Daten finanzieller Natur. In der Vergangenheit handelte es sich dabei größtenteils um quantitative Daten, die spezifisch für Unternehmen und ihre Betriebsabläufe waren, z. B. Bilanzdaten, Daten aus der Gewinn- und Verlustrechnung und Cashflow-Daten.
Einige unserer Daten sind urheberrechtlich geschützt und umfassen kundenspezifische Methoden, Berechnungen und portfoliospezifische Daten. Wir arbeiten aber auch mit externen Daten, die von großen Anbietern wie Refinitiv, Bloomberg und FactSet stammen.
Wir beschäftigen uns auch zunehmend mit dem, was wir heute als alternative Daten bezeichnen. Während alternative Daten vor einigen Jahren noch aus obskuren Dingen wie Satellitenbildern vom Parkplatz eines Einzelhandelsunternehmens bestanden, umfassen sie heute beispielsweise wichtige Leistungsindikatoren sowie Umwelt-, Sozial- und Governance-Daten (ESG).
Mehr Daten, neue Herausforderungen
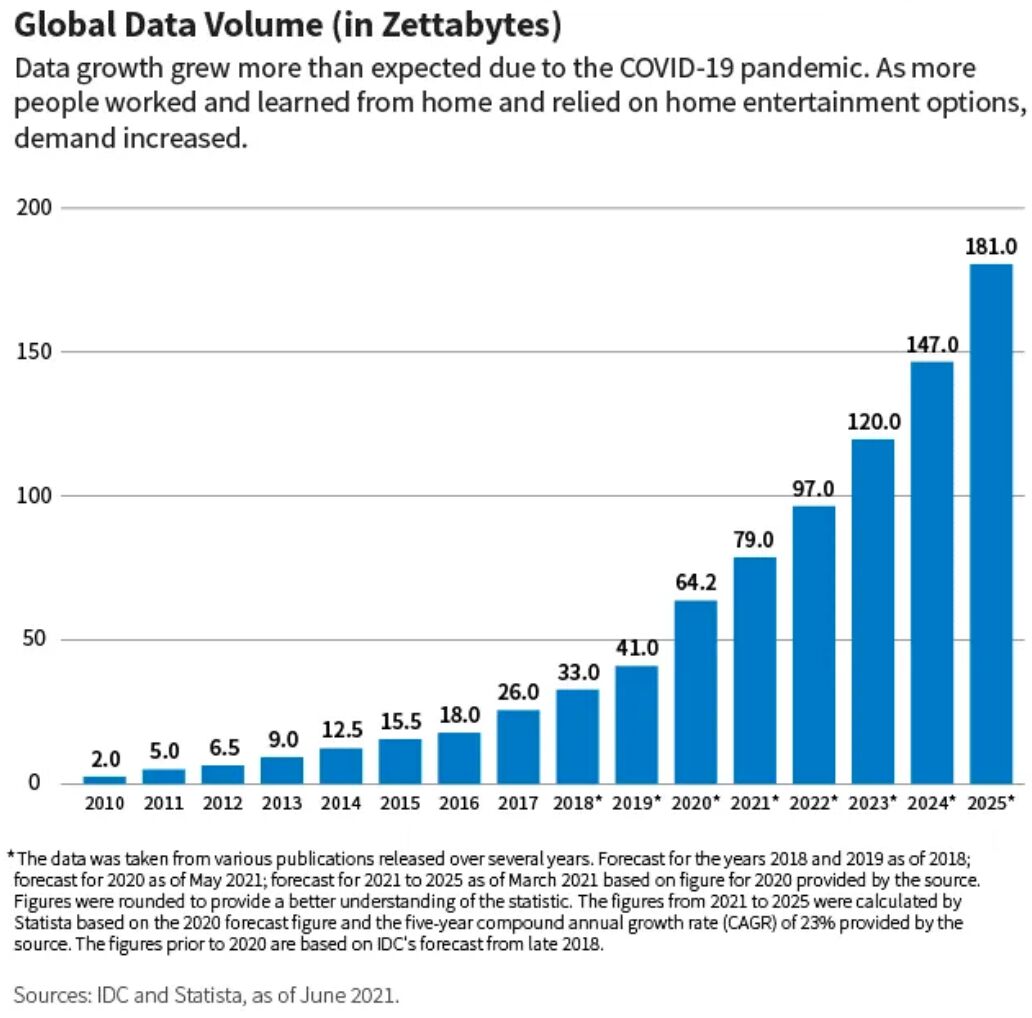
Heute gibt es viel mehr Daten als in der Vergangenheit. Die Gesamtmenge der weltweit erstellten, erfassten, kopierten und verbrauchten Daten wird Prognosen zufolge rapide ansteigen und im Jahr 2025 181 Zettabyte erreichen, wie die folgende Grafik zeigt.
Auch Rohdaten müssen bereinigt und aufbereitet werden, um nützlich zu sein. Für die Anwendung in der Anlageforschung müssen die Daten zusammengefügt und einem bestimmten Unternehmen oder Wertpapier zugeordnet werden, eine Aufgabe, die Data Engineering erfordert.
Außerdem ist es wichtig, die Daten in einem agnostischen Format zu verarbeiten und zu speichern, um den Kopieraufwand zu minimieren und die Anzahl der Zugriffsmedien, die die Daten lesen können, zu maximieren. Alternative Daten, wie Nachrichten und Stimmungsdaten, können subjektiv sein und sind schwieriger zu standardisieren und zu speichern.
Schließlich ist es wichtig, dass wir nicht für jede Aufgabe oder jedes Projekt dieselbe Arbeit wiederholen müssen. Es kann mehrere Anwendungsfälle für einen bestimmten Datensatz geben, und wir müssen sicherstellen, dass die Daten für alle Anwendungen leicht verfügbar sind, damit wir nicht für jeden Anwendungsfall die gleiche Arbeit wiederholen.
Die Demokratisierung von Daten ist der Schlüssel
Bei dem Versuch, diese Herausforderungen zu lösen, teilen wir Daten und erweitern die Zugangsmedien. Das ist das Konzept der Datendemokratisierung: vielen Endnutzern den Zugang zu Daten ermöglichen und gleichzeitig die Barrieren zwischen dem Nutzer und den Daten minimieren. Die Endnutzer, z. B. Forschungsanalysten, können die Daten dann in ihre Finanzmodelle oder Business-Intelligence-Tools (BI) wie Power BI und Tableau einbetten und weitere Analysen durchführen, ohne dass sie einen Technologen oder Entwickler benötigen. Die Entwickler wiederum können in verschiedenen Umgebungen auf die Daten zugreifen, sei es über eine REST-API, Python oder R. Die Minimierung der Barrieren zwischen dem Nutzer und den Daten trägt zu einer skalierbaren Demokratisierung der Daten bei.
In der Vergangenheit konnten unsere Kollegen dies bis zu einem gewissen Grad tun, aber es war nicht immer einfach und zeitaufwändig. Aber die Fortschritte in der Technologie werden die Datendemokratisierung in Zukunft einfacher machen.
Erstellen eines Datensees
Ein Schritt, den wir in Richtung Datendemokratisierung unternommen haben, ist die Einführung und Übernahme neuer Cloud-basierter Technologien und Entwicklungen, so dass wir jetzt über einen produktionsbereiten Data Lake verfügen, um den Datenzugang der nächsten Generation zu schaffen.
Ein Data Lake ist ein Repository für Daten, die in ihrem natürlichen oder rohen Format gespeichert werden. Die Daten fließen aus verschiedenen Quellen über unseren Data Lake in eine Verbrauchszone, wo sie für den einfachen Zugriff zur Verfügung gestellt werden. Dieser Datenflussprozess ist standardisiert und wiederholbar und reduziert die Notwendigkeit, Daten zu kopieren. Außerdem ermöglicht er ein besseres Management der Datenqualität.
Data Lakes können nicht nur größere Datenmengen aufnehmen, sondern dies auch zu geringeren Kosten im Vergleich zu Data Warehouse-Alternativen. Indem Sie Ihre Datenspeicherung von Ihrer Datenverarbeitungstechnologie trennen, sie aber dennoch in unmittelbarer Nähe halten, können Sie weitere Vorteile bei der skalierbaren Demokratisierung von Daten erzielen.
Arbeiten mit bestehenden und neuen Daten
Wie funktioniert die Datendemokratisierung mit bestehenden, kuratierten Daten? Ein Beispiel stammt von unserem quantitativen Forschungsteam, das eine Bibliothek mit quantitativen Faktoren und Modelldaten entwickelt hat, die von allen Teams in ihrer Forschung verwendet werden. Diese Datenbibliothek war zuvor nur in geschlossenen oder halboffenen Systemen mit proprietären Datenformaten verfügbar. Jetzt können sie leichter gemeinsam genutzt werden, und andere Teams können ohne weiteres darauf zugreifen und sie direkt in ihre Analysen einbeziehen.
Die Demokratisierung der Daten ermöglicht auch eine schnellere Verarbeitung und Nutzung neuer Daten. Wir arbeiten zum Beispiel mit einer Reihe neuer Datensätze, darunter Daten zu Treibhausgasemissionen auf Unternehmens- und Portfolioebene. Konkret bieten wir Zugang zu Emissionskennzahlen für Unternehmen, damit Analysten diese in ihre Fundamentalanalyse einbeziehen können. Dazu gehören die induzierten Scope 1-, 2- und 3-Emissionen (und die vermiedenen Emissionen, wenn Produkte/Dienstleistungen Effizienz oder Dekarbonisierung ermöglichen). Wir beginnen auch, die Daten zu nutzen, um Indikatoren auf Portfolioebene zu verstehen, damit Portfoliomanager Risiken und Chancen im Zusammenhang mit der Energiewende messen können. All dies setzt voraus, dass wir die Daten für einen einfachen Zugang und eine einfache Analyse gemeinsam nutzen, und das können wir dank unserer Bemühungen um eine Demokratisierung der Daten tun.
Verbesserung bestehender Prozesse
Die Datendemokratisierung kann auch bestehende Prozesse verbessern. Ein Beispiel: Einer unserer Analysten muss die von zahlreichen Unternehmen gemeldeten Quartals- und Jahresdaten vergleichen. Da diese Unternehmen unterschiedliche Geschäftsjahre und Berichtszyklen haben, ist es schwierig, Äpfel mit Äpfeln zu vergleichen, ohne die Daten zu manipulieren. Als es zu zeitaufwändig wurde, dies in Excel zu tun, bat die Analystin mein Team um Hilfe. Wir stellten ihr die Rohdaten zur Verfügung und dachten, das Projekt sei abgeschlossen, bis sie erwähnte, dass sie nicht über die nötigen Programmierkenntnisse verfügte, um die Daten weiter zu bearbeiten. Die Demokratisierung von Daten kann also viele Schritte umfassen - es handelt sich nicht um eine Verbesserung nach dem Motto "Einstellen und vergessen".
Fit für die Zukunft
Durch die Weiterentwicklung von Technologielösungen wird es nun einfacher, die Zeit, die für den Zugriff auf Daten aufgewendet wird, auf die Datenanalyse zu verlagern, und unsere Bemühungen um die Demokratisierung von Daten können unseren Kollegen (und letztendlich unseren Kunden) in vielerlei Hinsicht zugute kommen.
Erstens können unsere Kollegen über ein Selbstbedienungsmodell direkt auf die Daten zugreifen und sie analysieren. Kürzlich erhielt zum Beispiel ein Vertriebsmitarbeiter eine Frage von einem potenziellen Kunden. Sein Anlageausschuss hatte für einen Index ein wesentlich niedrigeres Kurs-Gewinn-Verhältnis (KGV) ermittelt als wir. Deshalb haben wir die Daten der Komponenten herangezogen, die Berechnung des Kurs-Gewinn-Verhältnisses aufgeschlüsselt und dann erklärt, wie man es berechnen kann, um eine Zahl zu erhalten, die näher an derjenigen liegt, die der potenzielle Kunde berechnet hatte - und das alles, ohne einen Entwickler hinzuzuziehen.
Zweitens verbringen unsere Kollegen weniger Zeit mit dem Abrufen und Zusammenfügen von Daten, was ihre Arbeitsabläufe verbessert. Die Zeit wird vom Sammeln von Informationen auf die Analyse und das Treffen von Entscheidungen verlagert.
Drittens senkt die Effizienz der Technologie und der Prozessabläufe die Kosten, was wiederum unseren Kunden zugute kommt.
Die Investition in Technologie zur Erleichterung einer skalierbaren Datendemokratisierung wird Vermögensverwalter in die Lage versetzen, mit weniger Ressourcen mehr zu tun, als sonst erforderlich wäre. Dies ist ein neuer und sich entwickelnder Bereich, und wir sind gespannt, wohin er die Vermögensverwaltungsbranche führen wird. Wir wollen die Computer bis an die Grenzen ihrer Möglichkeiten bringen und dann als Menschen einspringen, um das zu tun, was Computer nicht können. Und ich glaube, wir machen große Fortschritte.
Bleiben Sie dran für einen zukünftigen Blogbeitrag über die wichtigsten Lektionen, die wir aus unseren Bemühungen um die Datendemokratisierung gelernt haben.
Kristina Blaschek ist Direktorin für Geschäfts- und Technologielösungen bei William Blair Investment Management.
Weitere beliebte Meldungen:



