

Wesentliche Erkenntnisse
• Mehr Nutzer, eine hohe Nutzungshäufigkeit, eine deutlich höhere Komplexität pro Aufgabe und anhaltende Zeitsensitivität bringen den Tokenverbrauch auf eine Entwicklung, die jedes realistische Angebotswachstum übertrifft.
• Da Rechenleistung an kritischen Engpässen begrenzt ist, scheint sich der Markt von der Subventionierung von Tokens hin zu echter Preisfindung zu bewegen.
• Wir sind der Ansicht, dass der Übergang zu positiven Unit Economics wahrscheinlich nicht linear verlaufen wird. Genau hier könnten unser aktives Portfoliomanagement und unser Fokus auf attraktive Risiko Rendite Chancen Vorteile gegenüber einem passiven Investmentansatz bieten.
Ob Cloud Service Provider eine angemessene Rendite auf ihre Investitionen in KI-Infrastruktur erzielen werden, ist eine der folgenreicheren Fragen im heutigen Marktumfeld. Microsoft, Google, Amazon und Meta haben gemeinsam Investitionsausgaben, Capex, von nahezu 650 Milliarden US-Dollar allein für 2026 in Aussicht gestellt, wobei ein erheblicher Teil in KI-bezogene Infrastruktur fließen soll.
Das Ausmaß dieser Investitionen ist Investoren durchaus bewusst, doch wird die Rechnung aufgehen?
Wir sind der Ansicht, dass die Antwort darin liegt, zwei Dinge gleichzeitig zu verstehen: die außergewöhnliche und weitgehend unbeschränkte Natur der Nachfrage nach KI-Rechenleistung und die strukturellen Angebotsbeschränkungen, die die Preisfindung in den kommenden Jahren prägen werden.
Zusammen dürften diese Faktoren aus unserer Sicht die Grundlage für eine deutliche Verbesserung der Unit Economics von KI-Infrastruktur schaffen. Diese Entwicklung weist Parallelen zu einem Verlauf auf, der sich vor einem Jahrzehnt in einer anderen disruptiven Branche gezeigt hat.
Nachfrage: Eine Chance über mehrere Größenordnungen hinweg
Die Währung der KI-Rechenleistung ist der Token, eine diskrete Texteinheit, die darstellt, wie Sprachmodelle Informationen „sehen“ und verarbeiten. Statt vollständige Sätze so zu lesen wie Menschen, zerlegen Sprachmodelle Sprache in Tokens, etwa einzelne Wörter, Wortbestandteile oder sogar Satzzeichen, und verarbeiten diese Einheiten sequenziell. Tokens sind zudem die grundlegende Einheit, anhand derer Rechenaufwand, Kosten und Leistung gemessen werden.
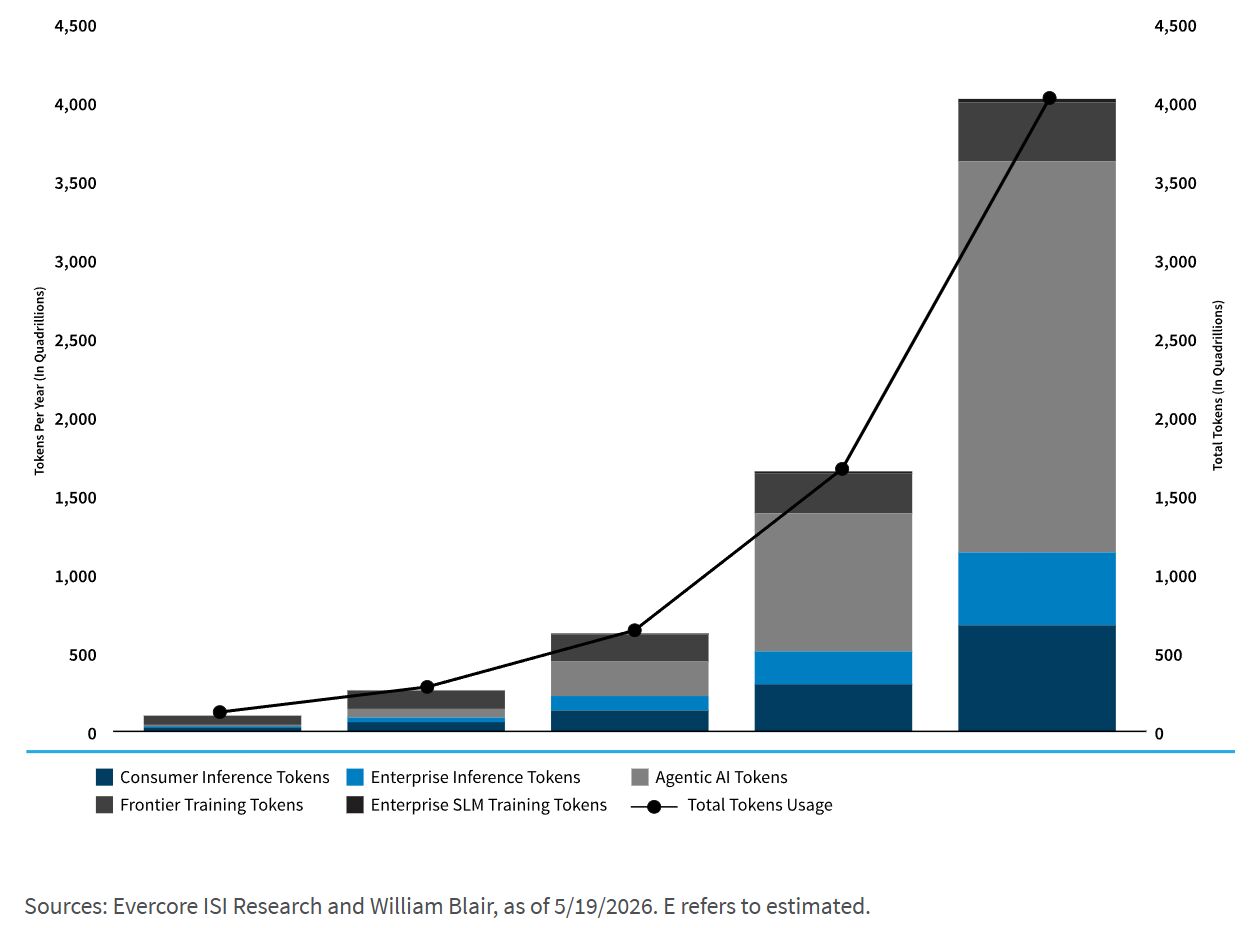
Darüber hinaus verbraucht jede Chatbot Antwort oder jede Entscheidung eines autonomen Agenten Tokens. Die Nachfrage nach diesen Tokens wird von vier sich gegenseitig verstärkenden Variablen getrieben, die jeweils wachsen und sich vervielfachen.
1. Nutzer
Konsumentenorientierte KI hat bereits eine bedeutende Größenordnung erreicht. Alphabet berichtete zuletzt von rund 900 Millionen monatlich aktiven Gemini Nutzern, gegenüber etwa 750 Millionen Nutzern im vierten Quartal 2025.1 Auch OpenAI und Anthropic haben ähnlich starke Zuwächse bei der Nutzerzahl verzeichnet. Doch die Konsumentenschicht ist nur die sichtbarste Ebene. Die Nutzung in Unternehmen, wo KI typischerweise unter anderem zur Automatisierung von Arbeitsabläufen und zur Unterstützung von Entscheidungsprozessen eingesetzt wird, befindet sich noch in einer frühen Phase.
Wenn Unternehmen von der Experimentierphase zur operativen Implementierung übergehen, dürften Anwendungsfälle in Unternehmen zu einem wichtigen zusätzlichen Treiber der Token Erzeugung werden, sowohl für Kosteneinsparungen als auch für die Schaffung von Erlösen. Selbst unter konservativen Annahmen könnte die Gesamtzahl der KI Nutzer um ein Mehrfaches steigen, sobald die Nutzung in Unternehmen Fahrt aufnimmt.
2. Häufigkeit
Der durchschnittliche Nutzer eines allgemeinen Chatbots interagiert heute möglicherweise einige Male pro Woche damit. Vergleicht man dies jedoch mit einem autonomen System wie selbstfahrenden Fahrzeugen oder KI gestützten Kundenservice Plattformen, können Interaktionen in die Tausende pro Stunde gehen.
Da KI in alltägliche geschäftliche und private Arbeitsabläufe eingebettet wird, könnte sich die Nutzungshäufigkeit auf globaler Basis plausibel um das 100-Fache gegenüber dem heutigen Niveau ausweiten, wenn sich KI von einem Werkzeug, das Menschen gelegentlich nutzen, zu einer Infrastruktur entwickelt, die kontinuierlich läuft.
3. Komplexität
Bei der Komplexitätsvariable werden die Zahlen tatsächlich beeindruckend. Eine einfache Chatbot Anfrage verbraucht beispielsweise Hunderte von Tokens, während eine mehrstufige agentische KI Aufgabe Millionen verbrauchen kann. Noch mehr: Autonome Systeme, die kontinuierlich in Unternehmensumgebungen laufen, könnten Hunderte Millionen Tokens pro Aufgabenzyklus verbrauchen.
Der Wandel von einfachen Frage Antwort Schnittstellen hin zu komplexen, multimodalen Multi Agenten Workflows bedeutet einen potenziellen Anstieg des Tokenverbrauchs pro Interaktion um sechs Größenordnungen oder mehr.
Effizienzverbesserungen sind real. Modelle leisten heute pro Token mehr als noch vor zwei Jahren, und dieser Trend wird sich fortsetzen. Doch Effizienzgewinne dürften kaum mit der Breite und Tiefe der neuen Anwendungsfälle Schritt halten, die nun hinzukommen. Die Nettonachfrage nach Tokens, selbst nach Berücksichtigung von Effizienzgewinnen, bewegt sich auf einer Entwicklung, die die aktuelle Rechenkapazität weit übersteigt.
4. Zeitsensitivität
Zeitsensitivität dürfte weiterhin eine konstante Variable bleiben. Nutzer und Unternehmen wollten schon immer schnellere Antworten, und dieser Druck dürfte kaum nachlassen, da er eine anhaltend steigende Nachfrage nach Infrastrukturen mit geringerer Latenz und höherem Durchsatz schafft. Dies wiederum erfordert mehr Rechenleistung, nicht weniger.
Zusammen dürften diese Kräfte in den kommenden Jahren zu einer deutlichen Ausweitung der Token Nutzung führen, wie unten dargestellt.
Geschätzte jährliche Token Nutzung zwischen 2026 und 2030
Angebot: Beschränkt, aber auf dem Weg in die Preisfindung
Die Angebotsseite der Token Gleichung ist deutlich weniger elastisch als die Nachfrageseite. KI-Rechenleistung läuft durch eine enge Reihe von Engpässen.
Der erste ist die Wafer Produktion von Taiwan Semiconductor, TSMC. Wafer sind dünne, kreisrunde Siliziumscheiben, die als Ausgangsmaterial für Chips dienen, und die Kapazitäten von TSMC für fortschrittliche Fertigungsknoten benötigen Jahre, um online zu gehen, und können nicht rasch als Reaktion auf Nachfragespitzen erweitert werden.
Als Nächstes folgen die Chip Architekturen von Nvidia, AMD, Broadcom und anderen. Softwareverbesserungen und Optimierungen haben bei jeder Generation von Chip Architekturen zu einem besseren Token Durchsatz geführt, doch sprunghafte Leistungsverbesserungen kommen typischerweise erst mit neuen Chip Generationen. Das Chip Ökosystem versucht daher mittlerweile, neue Chip Generationen in einem ungefähr jährlichen Rhythmus bereitzustellen. Da jedoch die Komplexität des Chips und des Systems, in dem der Chip eingesetzt wird, steigt, wird es zunehmend schwieriger, die Zeitpläne der Roadmaps einzuhalten.
Der letzte Engpass sind die Bauzyklen von Rechenzentren, bei denen die Nachfrage von Hyperscalern, staatlichen KI-Programmen und Unternehmen weiterhin schneller wächst als die Verfügbarkeit von Komponenten.
Diese Angebotsinelastizität hat eine wichtige Folge: Erstmals könnte der Markt in eine Phase der Preisfindung für Tokens eintreten. Während der vergangenen zwei Jahre war die vorherrschende Dynamik weitgehend Preiswettbewerb und Token Subventionierung, wobei die Inferenzkosten stark zurückgingen, da Anbieter um Marktanteile konkurrierten.
Diese Dynamik beginnt sich zu verändern. Der jüngste Schritt von Anthropic in Richtung nutzungsbasierter Preisgestaltung, etwa durch die Ergänzung pauschaler Abonnementstufen um Pay per Token Modelle, ist ein frühes und bedeutendes Signal.
Da die Nachfrage nach Tokens strukturell schneller wächst als das Angebot an Tokens, werden Anbieter es sowohl als notwendig als auch als wirtschaftlich rational ansehen, sie näher an markträumenden Niveaus zu bepreisen. Die Ära subventionierter Tokens könnte zu Ende gehen, und der markträumende Preis dürfte der Mechanismus sein, über den die Renditen auf Investitionen in Rechenleistung letztlich gemessen werden.
Die Rideshare Analogie: Von der Landnahme zu Unit Economics
Das Muster innerhalb der KI-Infrastruktur hat ein jüngeres und lehrreiches Vorbild: die Rideshare Branche.
In den frühen Jahren des Ridesharing konnten Uber und Lyft Fahrten stark subventionieren, da die Unternehmen durch Risikokapital und Wachstumsmandate um jeden Preis unterstützt wurden. Fahrpreise wurden unter den Kosten angesetzt, und Fahrer erhielten Anreizzahlungen, die durch die zugrunde liegende Wirtschaftlichkeit nicht getragen wurden.
Das Ziel war Skalierung, und das erwies sich als erfolgreich. Doch sobald Ridesharing eine kritische Masse erreicht hatte, wurden die Subventionen zurückgefahren. Preise stiegen, und Fahreranreize wurden rationalisiert. Das Geschäftsmodell, das lange als dauerhaft unwirtschaftlich verspottet worden war, begann, echte Cashflows zu generieren. Uber erzielte 2023 seinen ersten ganzjährigen Gewinn nach GAAP.
Heute verfolgen Cloud Anbieter ein auffallend ähnliches Vorgehen. Inferenz, also die Phase, in der ein KI-Modell genutzt wird, um aus Eingaben Ergebnisse zu erzeugen, wird zu, nahe an oder unter den Kosten bepreist, um die Nutzung zu beschleunigen, Unternehmenskunden den ROI zu demonstrieren und Entwicklerökosysteme an sich zu binden. Mit anderen Worten: Die Hyperscaler subventionieren derzeit die KI Landnahme mit ihren Bilanzen. Das ist kein irrationales Verhalten, sondern eine rationale Investition in die langfristige Plattformpositionierung.
Die Fragen, die Investoren aus unserer Sicht stellen sollten, lauten, wie lange effektive Subventionen bestehen bleiben und wie turbulent der Übergang zu positiven Unit Economics verlaufen wird. In diesem Fall bietet die Rideshare Analogie wichtige Nuancen, denn der Übergang verlief nicht linear. Es gab Fehlstarts, wettbewerbliche Rückschläge und Phasen mit Margendruck, bevor die Unit Economics klar erkennbar wurden.
Fazit: Die Renditefrage
Wir sind der Ansicht, dass die Rendite auf Ausgaben für Cloud KI-Infrastruktur letztlich davon abhängt, ob Token Preise auf Niveaus steigen können, die das eingesetzte Kapital rechtfertigen. Aus unserer Sicht sind die strukturellen Bedingungen für dieses Ergebnis zunehmend vorhanden, und die Nachfrage nach Tokens wächst schneller, als es durch eine vernünftigerweise erwartbare Angebotsausweitung aufgefangen werden kann. Der Markt beginnt zudem den beobachtbaren Prozess der Preisfindung, wobei nutzungsbasierte Preisgestaltung ein früher Beleg für diesen Wandel ist.
Die Risiken sind natürlich real. Die Modelleffizienz könnte sich schneller verbessern als erwartet, wodurch die Token Intensität pro Arbeitslast sinken würde. Neue Marktteilnehmer in der Chip Fertigung könnten die Angebotsbeschränkung im Zeitverlauf ebenfalls deutlich lockern, während sich die Nutzung in Unternehmen langsamer oder uneinheitlicher entwickeln könnte, als die aktuelle Begeisterung nahelegt.
Diese Nichtlinearität zu navigieren, ist aus unserer Sicht ein Bereich, in dem diszipliniertes aktives Management seinen Platz verdient. Für Investoren, die die langfristige Wirtschaftlichkeit der Hyperscaler Capex beurteilen, sind aufschlussreiche Fragen, ob der Markt Dauer und Ausmaß der bevorstehenden Nachfragekurve korrekt einpreist und ob der Mechanismus der Preisfindung, der nun zu wirken beginnt, ein ebenso starker Motor der Wertschöpfung sein wird, wie es das Rideshare Vorbild nahelegt.
Darüber hinaus fordern wir uns selbst heraus, kreativ über die mögliche Dauer des Wachstums nachzudenken, das mit diesem einzigartigen und kraftvollen Zyklus verbunden ist.
Diese Fragen stehen im Zentrum unseres Investmentprozesses. Wir sind der Ansicht, dass Outperformance daraus entsteht, in strukturell begünstigte Wachstumsunternehmen zu investieren, deren Aktien attraktive Risiko Rendite Chancen bieten, und nicht einfach daraus, Unternehmen zu halten, die aufgrund ihrer Verbindung zu beliebten Marktthemen starke Dynamik aufweisen.
Darüber hinaus hilft uns unser Fokus auf starke Managementteams, nachhaltige Geschäftsmodelle und attraktive Finanzkennzahlen dabei, potenziell dauerhafte Franchises zu identifizieren. Der Prozess, unsere strengen fundamentalen Prognosen gegen einen disziplinierten Bewertungsrahmen abzuwägen, hilft uns wiederum zu bestimmen, was wir letztlich für sie bezahlen sollten.
In einem Zyklus dieser Größenordnung liegt aus unserer Sicht genau in dieser Disziplin die Möglichkeit, dauerhaftes Alpha zu finden.
Christopher Sweeney, CFA, ist Research Analyst im U.S. Growth and Core Equity Team von William Blair.
Möchten Sie mehr Einblicke in die Wirtschaft und die Investitionslandschaft? Abonnieren Sie hier den William Blair Investment Management Blog
Weitere beliebte Meldungen:



1 Quelle: Google I/O 2026.
