

Wichtigste Erkenntnisse
- Der Ausbau der KI-Infrastruktur ist einer der größten Investitionszyklen der modernen Geschichte, unterstützt durch jährliche Investitionsausgaben (Capex), die bereits in die Hunderte Milliarden gehen: Hyperscaler, darunter Microsoft, Alphabet, Amazon, Meta und Oracle, dürften allein im Jahr 2026 zusammen nahezu 700 Milliarden US-Dollar für Capex ausgeben, wobei ein großer Teil dieser Investitionen in den Ausbau der KI-Infrastruktur fließt, um die wachsende Nachfrage nach KI-Rechenleistung zu unterstützen.
- Für aktive Manager geht die Anlagechance weit über die Hyperscaler selbst hinaus: Die KI-Lieferkette umfasst fünf unterschiedliche Ebenen, nämlich Halbleiter, Netzwerke, Strom/Energie, Kühlung und physische Bauinfrastruktur. Jede dieser Ebenen verfügt über überzeugende Wachstumstreiber und Unternehmen, die aus unserer Sicht von einer dauerhaften, strukturellen Nachfrage profitieren können.
In den vergangenen mehreren Jahren konzentrierte sich das KI-Investmentnarrativ weitgehend auf eine kleine Gruppe von Hyperscale-Technologieunternehmen, deren Aktienkurse im Allgemeinen in Erwartung der Produktivitäts- und Umsatzvorteile gestiegen sind, die KI voraussichtlich generieren wird.
Wir sind jedoch der Ansicht, dass diese Konzentration der Aufmerksamkeit eine breitere Chance verdeckt hat, die sich über die KI-Lieferkette erstreckt.
Die Ausgangslage: Das Ausmaß des KI-Ausbaus
In den vergangenen mehreren Jahren haben große Hyperscaler robuste Capex-Zusagen angekündigt. Microsoft, Alphabet, Amazon, Meta Platforms und Oracle haben gemeinsam signalisiert, jährlich Hunderte Milliarden US-Dollar in KI-bezogene Infrastruktur investieren zu wollen, darunter den Bau von Rechenzentren, die Beschaffung von Halbleitern, Netzwerkausrüstung und Strominfrastruktur.1
Entscheidend ist, dass die Managementteams jedes dieser Unternehmen betont haben, dass diese Zusagen mehrjähriger Natur sind und es sich nicht um diskretionäre Ausgaben handelt, die schnell gekürzt werden können. Diese Capex-Zusagen werden als strategische Investitionen inmitten eines generationenprägenden Plattformwechsels betrachtet, der durch den Ausbau und die Nutzung von KI vorangetrieben wird. Wie die untenstehende Grafik zeigt, dürften die Capex-Ausgaben großer Hyperscaler allein im Jahr 2026 fast 700 Milliarden US-Dollar erreichen.
Hyperscaler-Capex-Ausgaben (in Milliarden)
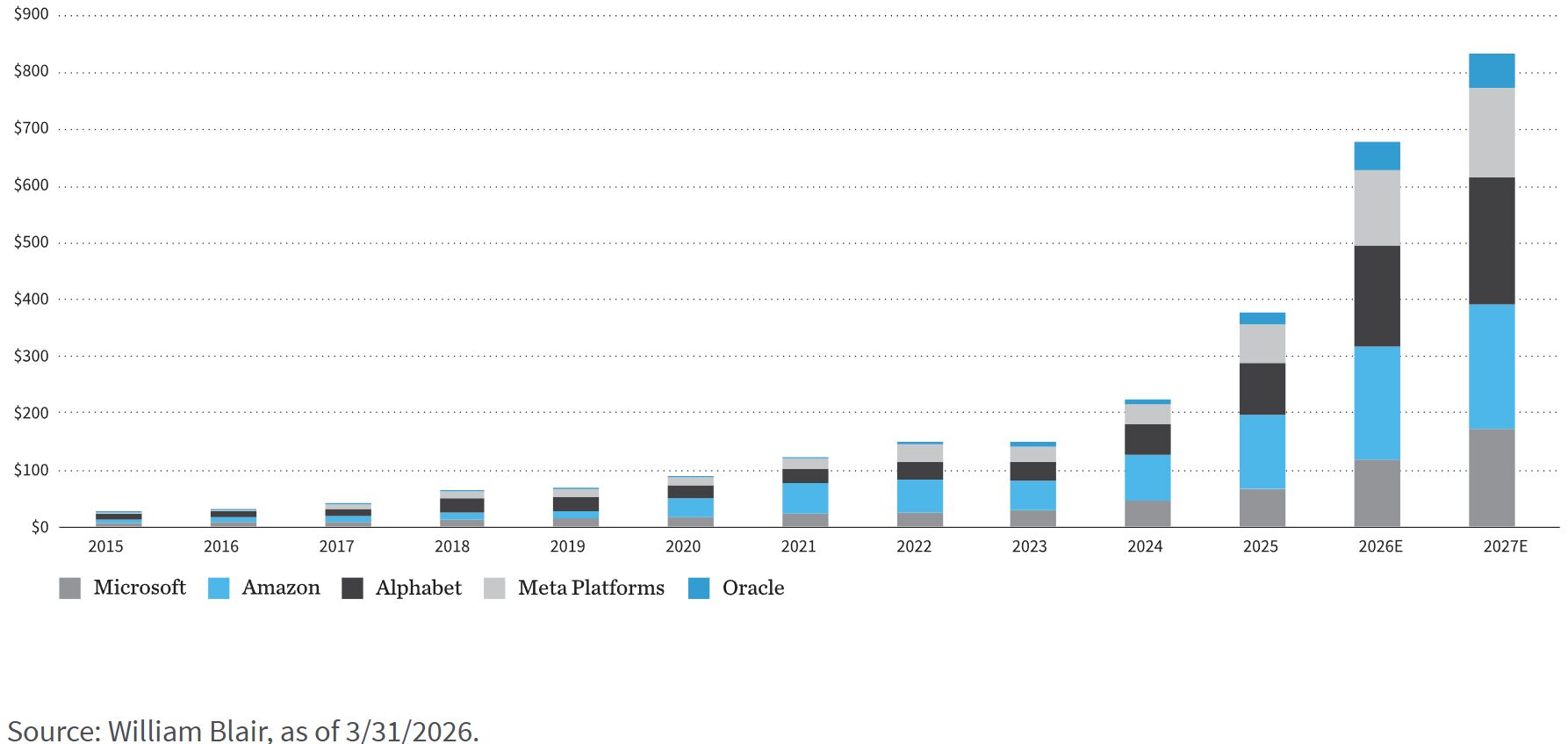
Was diesen Capex-Zyklus von früheren Wellen technologischer Investitionen unterscheidet, etwa dem Dotcom-Ausbau der späten 1990er-Jahre und der Cloud-Migration der 2010er-Jahre, ist das Zusammentreffen mehrerer gleichzeitiger Faktoren:
Die Rechenintensität von Trainings- und Inferenz-Workloads ist um Größenordnungen höher als bei früheren Unternehmenssoftware-Anwendungen. KI-Training erfordert typischerweise massive Datensätze, spezialisiertes Talent und eine teure Recheninfrastruktur, was die Teilnahme auf eine kleine Gruppe großer Technologieunternehmen und gut ausgestatteter Firmen begrenzen kann. KI-Inferenz ist demgegenüber günstiger und einfacher einzusetzen, sodass deutlich mehr Unternehmen KI in ihren Produkten und Abläufen nutzen können. Die Verlagerung vom KI-Training zur KI-Inferenz erweitert den Zugang über ein breiteres Spektrum von Unternehmen und Nutzern hinweg und vergrößert den adressierbaren Markt erheblich.
Der Energiebedarf von KI-Rechenzentren schafft physische Infrastrukturengpässe, deren Behebung wahrscheinlich Jahre und nicht Monate dauern wird.
Geopolitischer Druck treibt die Rückverlagerung der Halbleiterfertigung in heimische Märkte und die Diversifizierung der Lieferketten voran und schafft damit zusätzlich zu den KI-Ausgaben eine strukturelle Nachfrageschicht.
Darüber hinaus haben sich Rechenzentren in den vergangenen Jahren rasch ausgeweitet. Schätzungen zufolge dürften bis Ende 2026 weltweit 8.800 Anlagen in Betrieb sein.2 Diese Gesamtzahl verteilt sich auf mehr als 170 Länder und wird von den Vereinigten Staaten angeführt, auf die fast die Hälfte aller Installationen entfällt.
Auch die erwartete Wachstumsentwicklung bis zum Ende des Jahrzehnts ist beträchtlich. ABI Research prognostiziert, dass bis 2030 mehr als 10.000 Rechenzentren in Betrieb sein werden, wobei die Zahl der Hyperscale-Anlagen, also großflächiger Campusstrukturen, die von Cloud- und KI-Unternehmen betrieben werden, auf mehr als 3.200 steigen dürfte.3
Entscheidend ist, dass die reine Anzahl der Anlagen das Ausmaß der Expansion unterschätzt. Die weltweite Rechenzentrumskapazität dürfte bis 2030 rund 200 Gigawatt (GW)4 erreichen und sich damit gegenüber dem aktuellen Niveau nahezu verdoppeln, da in den kommenden fünf Jahren rund 100 GW an neuer Kapazität hinzukommen dürften.5
Zur Einordnung: Die zusätzliche elektrische Leistungskapazität, die neue Rechenzentren zwischen heute und 2030 benötigen könnten, zusätzlich zu den rund 100 GW, die heute bereits in Betrieb sind, entspricht in etwa der gesamten Stromerzeugungskapazität Deutschlands. Das ist genug Strom, um etwa 75 Millionen durchschnittliche US-Haushalte dauerhaft zu versorgen.
Wir sind der Ansicht, dass das Kapital, das erforderlich ist, um diese Infrastruktur zu bauen, mit Energie zu versorgen und zu vernetzen, eine bedeutende und dauerhafte Chance entlang der KI-Lieferkette darstellt. Während der Ausbau bereits im Gange ist, besteht die wichtigere Frage für Investoren darin, zu identifizieren, welche Unternehmen am besten positioniert sind, um einen überproportionalen Anteil dieser Ausgaben auf sich zu vereinen.
Das Ökosystem der Wegbereiter: Elemente der KI-Lieferkette im Überblick
Die Lieferkette der KI-Infrastruktur lässt sich als eine Reihe unterschiedlicher, aber voneinander abhängiger Ebenen verstehen. Jede dieser Ebenen weist ein anderes Risiko-Rendite-Profil, eine andere Wettbewerbsdynamik und unterschiedliche Nachfragetreiber auf. Im Folgenden betrachten wir fünf unterschiedliche Ebenen der KI-Lieferkette, die beim Ausbau von Rechenzentren und KI eine entscheidende Rolle spielen.
1. Halbleiter und Komponenten
Am Fundament des Ausbaus der KI-Infrastruktur steht die Halbleiterebene, also die Chips und Komponenten, die KI physisch möglich machen. Die sichtbarsten davon sind Grafikprozessoren (GPUs), spezialisierte Prozessoren, die ursprünglich für Videospiele entwickelt wurden, sich aber als außergewöhnlich gut geeignet für die Art von Mathematik erwiesen haben, die KI-Modelle benötigen. Der Betrieb von KI-Workloads in großem Maßstab erfordert enorme Mengen dieser Chips: Ein einzelnes großes Rechenzentrum kann Zehntausende von GPUs beherbergen, von denen jede so viel Strom verbraucht wie ein Haushaltsgerät im Dauerbetrieb.
Während Nvidia als dominanter GPU-Anbieter den Großteil der Aufmerksamkeit der Investoren auf sich gezogen hat, reicht die Anlagechance in dieser Ebene weit über ein einzelnes Unternehmen hinaus. Jede GPU benötigt eine Reihe unterstützender Komponenten, um zu funktionieren. Chips für das Energiemanagement regulieren, wie Strom innerhalb eines Servers bereitgestellt und umgewandelt wird. Da Chips leistungsfähiger und stromhungriger geworden sind, sind auch die Komplexität und die Kosten dieses Stromversorgungssystems gestiegen.
High Bandwidth Memory (HBM) löst ein anderes Problem: Eine GPU kann Daten nur so schnell verarbeiten, wie diese aus dem Speicher abgerufen werden können. Daher sind die Chips, die diese Daten speichern und bereitstellen, ebenso wichtig wie der Prozessor selbst. Die Nachfrage nach HBM hat das Angebot seit der Beschleunigung des KI-Ausbaus durchgehend übertroffen.
Die folgenreichste längerfristige Entwicklung besteht darin, dass einige der größten Technologieunternehmen, nämlich Amazon, Google, Microsoft und Meta, jeweils begonnen haben, eigene kundenspezifische Chips zu entwickeln, die speziell auf ihre Workloads zugeschnitten sind, anstatt sich vollständig auf standardisierte GPUs zu verlassen. Dadurch entsteht eine neue und wachsende Nachfragequelle, die durch ein breiteres Netzwerk von Halbleiterzulieferern fließt: Chipdesigner, spezialisierte Hersteller und Anbieter fortschrittlicher Packaging-Technologien, die jede neue Siliziumgeneration vom Design in die Produktion bringe.
2. Netzwerke und Konnektivität
Mit der Skalierung von KI-Workloads steigen die Bandbreitenanforderungen zwischen Rechenknoten, über Rechenzentren hinweg und hinaus zu den Endnutzern exponentiell. Kupferbasierte elektrische Verbindungen sind zunehmend nicht mehr in der Lage, die Anforderungen moderner KI-Infrastruktur an Geschwindigkeit, Distanz und Energieeffizienz zu erfüllen.
Daher dürfte die laufende Verlagerung vom KI-Training, das weitgehend innerhalb einer einzelnen Anlage stattfindet, hin zur KI-Inferenz, die eine latenzarme Konnektivität über verteilte Infrastruktur hinweg erfordert, die Nachfrage nach breitbandiger Konnektivität in großem Maßstab, also nach Glasfaserkabeln, weiter beschleunigen.
Rechenzentren und Server müssen verbunden werden
3. Strom- und Energieinfrastruktur
Der vielleicht am stärksten unterschätzte Engpass beim KI-Ausbau ist Strom. Ein modernes KI-Rechenzentrum kann so viel Strom verbrauchen wie eine kleine Stadt, und das globale Stromnetz, insbesondere in den Vereinigten Staaten und Europa, wurde nicht dafür ausgelegt, dieses Ausmaß an zusätzlicher Nachfrage aufzunehmen.
Wir sind der Ansicht, dass dadurch überzeugende Anlagechancen entlang der Wertschöpfungskette im Strombereich entstehen. Einige Beispiele sind Industriegasunternehmen, deren Spezialgase für die Halbleiterfertigung und Kühlung unverzichtbar sind; Hersteller elektrischer Ausrüstung, die Transformatoren, Schaltanlagen und Stromverteilungssysteme produzieren; sowie das breitere Ökosystem der Netzmodernisierung.
Darüber hinaus fügt die Renaissance der Kernenergie, angetrieben durch Hyperscaler, die zuverlässige, CO2-freie Grundlastenergie suchen, diesem Thema eine weitere Dimension hinzu. Allein in den Vereinigten Staaten deuten Schätzungen auf rund 200 Terawattstunden (TWh) an neuer Stromnachfrage durch Rechenzentren bis 2030 hin.
Zur Einordnung: Ein einzelnes großes Kernkraftwerk erzeugt etwa 8 bis 10 TWh pro Jahr. 200 TWh würden daher die Leistung von ungefähr 25 Kernkraftwerken erfordern, die dauerhaft in Betrieb sind, genug Energie, um rund 18 Millionen durchschnittliche US-Haushalte ein ganzes Jahr lang mit Strom zu versorgen.
Energieverbrauch von US-Rechenzentren (TWh)
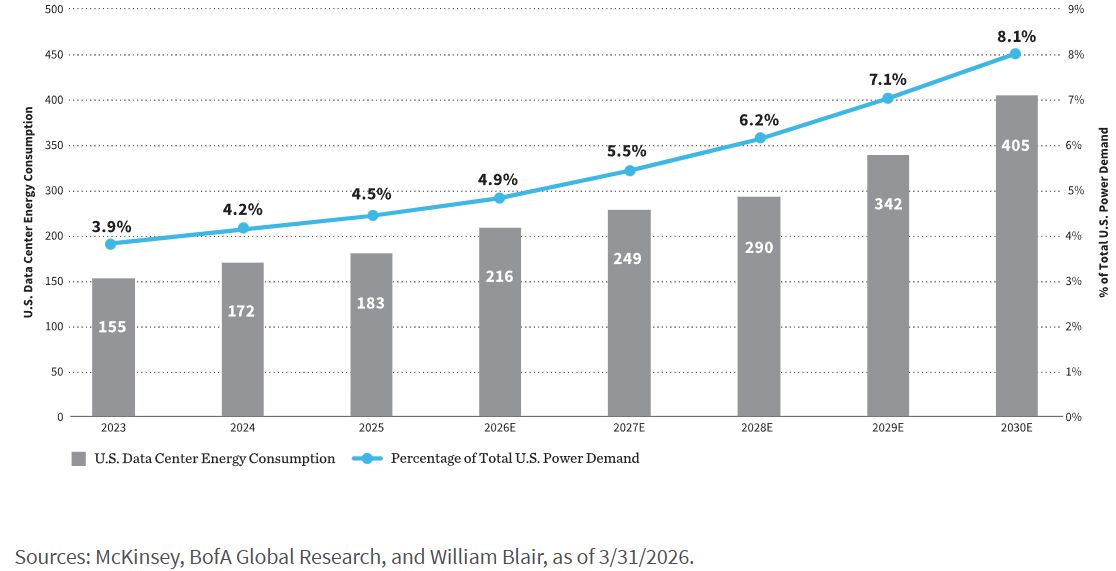
4. Kühlung und Wärmemanagement
Die Wärmedichte moderner KI-Rechencluster, getrieben durch den Stromverbrauch von High-End-GPUs, bringt traditionelle luftgekühlte Rechenzentrumsdesigns an ihre physischen Grenzen. Flüssigkeitskühlung, einschließlich direkter Flüssigkeitskühlung und Immersionskühlung, entwickelt sich von einer Nischenlösung zu einer zentralen Anforderung.
Flüssigkeitskühlung ist eine Methode des Wärmemanagements, bei der Flüssigkeit, typischerweise Wasser oder eine Kühlflüssigkeit, genutzt wird, um Wärme von Computerhardware wie GPUs und CPUs aufzunehmen und abzuleiten, und zwar effizienter als bei traditioneller Luftkühlung. Sie funktioniert, indem Kühlmittel durch Rohre oder Platten zirkuliert, die direkt an wärmeerzeugenden Komponenten angebracht sind. Direkte Flüssigkeitskühlung bringt das Kühlmittel in engen Kontakt mit dem Chip oder der Komponente selbst, zum Beispiel durch Kühlplatten, die direkt auf Prozessoren montiert sind, und ermöglicht dadurch eine sehr effiziente, gezielte Wärmeabfuhr. Immersionskühlung geht noch einen Schritt weiter, indem ganze Server oder Hardwarekomponenten direkt in eine wärmeleitende, elektrisch nicht leitfähige Flüssigkeit, etwa eine dielektrische Flüssigkeit, eingetaucht werden.
Wir sind der Ansicht, dass Unternehmen mit proprietärer Flüssigkeitskühlungstechnologie und etablierten Beziehungen zu Hyperscalern gut positioniert sind, um von dem zu profitieren, was einem wahrscheinlichen Upgrade-Zyklus in der weltweit installierten Rechenzentrumsbasis gleichkommt.
5. Physische Infrastruktur
Der physische Bau von KI-Rechenzentren ist selbst eine jährliche Chance im Milliardenbereich. Anders als bei traditionellem Gewerbebau erfordert die Entwicklung von KI-Rechenzentren spezialisiertes Know-how in hochdichten elektrischen Systemen, Präzisionskühlungsinfrastruktur und der Standortentwicklung, die jedem Gebäude vorausgeht, einschließlich Planierung, Versorgungseinrichtungen, Fundamenten und Zufahrtsstraßen.
Unternehmen mit nachgewiesener Erfolgsbilanz, engen Kundenbeziehungen zu Hyperscalern und vertikal integrierten Fähigkeiten in den Bereichen Standortentwicklung und Elektroinstallation gewinnen einen überproportionalen Anteil dieser Aufträge und bauen Auftragsbestände auf, die mehrjährige Umsatzvisibilität bieten können.
Wettbewerbsdynamiken und verteidigungsfähige Burggräben
Nicht alle Positionen in der Lieferkette der KI-Infrastruktur sind gleich geschaffen. Ein rigoroser Investmentrahmen erfordert die Unterscheidung zwischen Unternehmen mit dauerhaften Wettbewerbsvorteilen und solchen, deren kurzfristiges Umsatzwachstum eher zyklische Nachfrage als strukturelle Positionierung widerspiegelt.
Unternehmen, die innerhalb der KI-Lieferkette über Wettbewerbsvorteile verfügen, teilen mehrere Merkmale.
- Proprietäre Technologie: Proprietäre Technologie ist schwer zu replizieren und tief in die Arbeitsabläufe der Kunden integriert, und Halbleiterunternehmen verankern ihren Wert nicht nur im Silizium, sondern auch in Software-Ökosystemen. Eine dominante GPU-Plattform kann beispielsweise über mehr als ein Jahrzehnt hinweg eine starke Verankerung bei Entwicklern aufbauen, was bedeutet, dass Hyperscaler und KI-Labore ihre gesamte Trainingsinfrastruktur um sie herum aufbauen. Dies führt typischerweise dazu, dass die Wechselkosten für den Umstieg auf eine Alternative eher in Jahren der Neuentwicklung als in Dollar pro Chip gemessen werden.
- Langfristige Verträge: Darüber hinaus können langfristige Verträge dazu beitragen, Umsatzvisibilität zu schaffen und Unternehmen gegen preisdruckähnliche Dynamiken wie bei Rohstoffen abzuschirmen. Industriegaslieferanten beispielsweise arbeiten auf Basis jahrzehntelanger Vor-Ort-Verträge, die an die produktive Lebensdauer eines Vermögenswerts gekoppelt sind, und sichern sich dadurch wiederkehrende Umsatzströme, aus denen Kunden nur schwer aussteigen können. Diese Dynamik ist wichtig, da Flüssigstickstoff und Kohlendioxid zu kritischen Kühlungsinputs für hochdichte Server-Racks und KI-Recheninfrastruktur werden, die innerhalb von Rechenzentren intensive Wärme erzeugen.
- Skalenvorteile und Kundenkonzentration: Skalenvorteile entstehen bei Zulieferern entlang der KI-Wertschöpfungskette, die anschließend durch tiefe Integration, gemeinsame Entwicklung und die schieren Kosten eines Wechsels bei hohem Volumen fest in den Abläufen ihrer Kunden verankert werden. Hyperscaler sind das deutlichste Beispiel: Sie neigen dazu, ihre Lieferketten um eine kleine Zahl vertrauenswürdiger Anbieter zu konsolidieren, und Anbieter kundenspezifischer ASICs und Netzwerk-Siliziums werden strukturell eingebettet, sobald ein Hyperscaler eine Chiparchitektur gemeinsam mit ihnen um ihre Plattform herum entwickelt. Der Designzyklus dauert dann zwei bis drei Jahre, und die Wechselkosten entsprechen faktisch einer vollständigen Produktgeneration. Die Präferenz der Hyperscaler, sich auf eine Handvoll vertrauenswürdiger Anbieter zu konzentrieren, bedeutet, dass der etablierte Zulieferer nur selten einem wettbewerblichen Neuausschreibungsprozess ausgesetzt ist.
- Geografische und regulatorische Burggräben: Genehmigungszeiträume und Warteschlangen für Netzanschlüsse können bedeutende Eintrittsbarrieren für neue Wettbewerber schaffen, insbesondere beim Ausbau von Rechenzentren. Anbieter von Zuschlagstoffen profitieren beispielsweise davon, dass es nahezu unmöglich ist, neue Steinbrüche in der Nähe wachstumsstarker Rechenzentrumskorridore genehmigen zu lassen. Schotter kann wirtschaftlich nicht über mehr als rund 50 Meilen transportiert werden. Ein bestehender genehmigter Steinbruch in einem Markt mit begrenztem Angebot stellt daher einen dauerhaften, standortspezifischen Vorteil dar, den kein neuer Anbieter unabhängig vom verfügbaren Kapital replizieren kann.
Wir sind der Ansicht, dass Investoren bei Positionen in der Lieferkette vorsichtig sein sollten, bei denen die Wettbewerbsdifferenzierung primär preisbasiert ist; bei denen Produktzyklen kurz und Kundenwechselkosten niedrig sind; oder bei denen der Endmarkt den Kapitalallokationsentscheidungen eines einzelnen Hyperscalers ausgesetzt ist.
Zu beobachtende Risiken
Eine ausgewogene Einschätzung der Chance in der KI-Infrastruktur erfordert die Anerkennung der Risiken, die im Zeitverlauf zu Störungen führen könnten:
- Moderation der Capex-Ausgaben von Hyperscalern: Eine Verlangsamung der Ausgaben für KI-Infrastruktur, ob getrieben durch eine makroökonomische Verschlechterung, enttäuschende KI-Monetarisierung oder Verschiebungen in den Prioritäten der Kapitalallokation, stellt das bedeutendste Risiko für den Nachfrageausblick entlang der Lieferkette dar.
- Technologiesubstitution: Das rasche Tempo der Innovation bei KI-Modellen könnte bestimmte Hardwarearchitekturen schneller als erwartet obsolet machen und etablierte Zulieferer in den Halbleiter- und Netzwerkschichten unter Druck setzen.
- Geopolitische und lieferkettenbezogene Risiken: Die Konzentration der fortschrittlichen Halbleiterfertigung in Taiwan und Südkorea schafft Anfälligkeit für geopolitische Störungen, während sich Exportkontrollregime weiterentwickeln und die adressierbaren Märkte beeinflussen könnten.
Implikationen für die Portfoliokonstruktion
Für Aktieninvestoren bietet die KI-Lieferkette überzeugende Möglichkeiten, ein diversifiziertes Engagement in diesem starken langfristigen Wachstumstreiber aufzubauen und zugleich das Konzentrationsrisiko auszugleichen, das mit dem Besitz der Hyperscaler selbst einhergeht.
Diese Chancen erstrecken sich über das gesamte Marktkapitalisierungsspektrum, von Large-Cap-Infrastrukturführern, die Bilanzstärke und Visibilität durch vertraglich gesicherte Umsätze bieten, bis hin zu kleineren, spezialisierten Unternehmen, die häufig kritische, aber weniger sichtbare Bereiche der Lieferkette besetzen.
Wir sind der Ansicht, dass eine durchdachte Allokation über verschiedene Unternehmensgrößen hinweg sowohl die Beständigkeit etablierter Akteure als auch die differenzierte Positionierung aufstrebender Spezialisten entlang der Lieferkette erfassen kann.
Mehrere Prinzipien können die Portfoliokonstruktion innerhalb dieses Themas leiten:
- Diversifizierung über Lieferkettenebenen hinweg: Ein Portfolio mit Engagement über mehrere Ebenen der Lieferkette hinweg kann weniger anfällig für Störungen auf einer einzelnen Ebene sein als ein Portfolio, das auf ein einzelnes Segment konzentriert ist.
- Qualität des Burggrabens vor Wachstumsrate priorisieren: Wir sind der Ansicht, dass jene Unternehmen am ehesten dauerhafte Renditen erzielen können, die über verteidigungsfähige Wettbewerbspositionen verfügen, und nicht einfach jene mit dem schnellsten kurzfristigen Wachstum.
- Frühphasige Optionalität mit Umsatzvisibilität ausbalancieren: Einige der interessantesten Chancen können mit höherer Unsicherheit, aber auch mit größerem potenziellem Aufwärtspotenzial verbunden sein. Die Kombination solcher Chancen mit Unternehmen, die über einen starken vertraglich gesicherten Auftragsbestand verfügen, schafft ein ausgewogeneres Risikoprofil.
Abschließende Gedanken
Wir sind der Ansicht, dass der Ausbau der KI-Infrastruktur einen bedeutenden mehrjährigen Investitionszyklus darstellt. Während die Hyperscaler für diese Entwicklung zentral bleiben werden, stellen die Unternehmen, die den Ausbau ermöglichen, über Bereiche wie Halbleiter, Strom, Netzwerke, Kühlung und Bau, um nur einige zu nennen, ein breites und dynamisches Chancenspektrum dar, das unserer Ansicht nach Aufmerksamkeit verdient.
Während sich der Infrastrukturausbau weiter entfaltet, wird Selektivität beim Engagement wichtig bleiben. Wir sind der Ansicht, dass die Ausgaben für KI-Infrastruktur nicht linear wachsen werden und dass die Wettbewerbspositionierung dauerhafte Gewinner von zyklischen Teilnehmern unterscheiden wird.
Aaron Socker ist Portfoliospezialist im U.S.-Growth- und Core-Equity-Team von William Blair.
Möchten Sie mehr Einblicke in die Wirtschaft und die Investitionslandschaft? Abonnieren Sie hier den William Blair Investment Management Blog
Weitere beliebte Meldungen:



1 Verweise auf bestimmte Wertpapiere und deren Emittenten dienen ausschließlich illustrativen Zwecken. William Blair kann Wertpapiere der genannten Emittenten besitzen oder nicht besitzen, und sofern solche Wertpapiere gehalten werden, wird keine Zusicherung gegeben, dass diese Wertpapiere weiterhin gehalten werden. Die genannten Wertpapiere stellen nicht alle Wertpapiere dar, die für Beratungskunden gekauft, verkauft oder empfohlen wurden. Es sollte nicht davon ausgegangen werden, dass eine Anlage in die genannten Wertpapiere profitabel war oder sein wird.
2 Quelle: ABI Research.
3 Quelle: ABI Research.
4 GW bezieht sich auf Leistungskapazität: konkret auf die Menge an Strom, die ein Rechenzentrum beziehen kann, um seine Server, Kühlsysteme und sonstige Infrastruktur zu betreiben. Es ist die Standardeinheit, mit der die Branche die Größe von Rechenzentren misst, weil sie sowohl die Größe als auch die Intensität einer Anlage genauer erfasst als die Quadratmeterzahl allein.
5 Quelle: JLL.
